
(apr 7 '04) These routines come from when I used redhat 6.0 or so (quite some years ago), though they're fine, but in various ways varying stuff from such times is half broken or a bit off, at times, though I tried these scripts again myself, evidently.In-core databases (in a reasonable sense of that expression, not so small collections of data stored not on disc during access, search, update and manipulation) are interesting, and I always (from '93 or so on when I started with tcl) found a lisp like, strong enough language like it interesting to do database-like data manipulaton, without the often rather stringent and awkward 'real' database interfaces.See also:I just remembered some time ago thoughts have been about deep lsearch, and possibly I missed some 8.4 (or even 8.5) possibilities in this direction.
TV 31 mar 03: I found the routines all below are not all needed routines because my naming convention of prefixing was broken with at least one proc. All is in Bwise, though, except an example database (see bottom of page).In the Bwise library of routines (which is a fairly small file) there are routines which I made some not so incredibly raining afternoon and then some more when faced with a file with various data items which weren't easy to load into Lotus notes.The reason it is in the Bwise lib is that they can easily run in parallel, and that they can be used in a bwise graphical block which then represents a searchable database.First, the ideas. Mainly, tcl is well equiped to deal with very (in the line of tiny to mega huge) large amounts of list data, as are even modern PC's. Typing at 300 cpm, which I probably couldn't in a sustained way, one human computer owner would be able to produce 300*60*10 equals 175 kilobytes of input data in a long work day.So a database dealing with a day's worth of data would easily be an in-core database on even a pretty old and cheap PC. Modernly speaking, it's a lot worse, while putting your stamp collection in a database you could spent ten years of hard work, and would end up with 300*60*10*365*10 equals 626 megabytes of data. In ten years from now, THAT will fit easily in a PC's main memory, too, unless we're all nuked and the microprograms of the chip plants are erased forever by EMP.So why bother investing in difficult to program, maintain, and use disc based database systems for domestic and mild use. Let those bearings get a rest.(gna gna, we'll teach them who's the fastest and the most associative by design, too)I know databases aren't just typing and associativeness, but I liked to use the strong tcl machinery to have one main list, called dbvar (all routines are prefixed with db, this was before namespaces, or I just wasn't into them) which contains sublists, which are the equivalent of entries in a traditional database, which have sublists which contain field, name tuples in parallel with traditional fields in a record. Or was that records have entries with fields? I forgot.Anyhow, I made a three level list into the main data structure containing a database which can (I tested in the past on Mac G3's and simple enough compaq pc's) contain tens of thousands of records and be searched extensively, without keys, in seconds. On a contemporary PC, with hundreds of megabytes of main memory and far over a gig clock rates, that figure should be a lot better even, though I didn't test.
The general idea edit
Say we make a list which contains entries which have subentries: set dbvar {
{
{{some thing with a value} 1}
{{some other thing} 2}
} {
{one 1}
{two 2}
{three 3}
}
}The variable can simply be puts-ed of course, unless it is very big. The main entries are shown per page by calling the proceduredbaccesswith no parameters for using the default dbvar variable which we just filled with some stupid data.
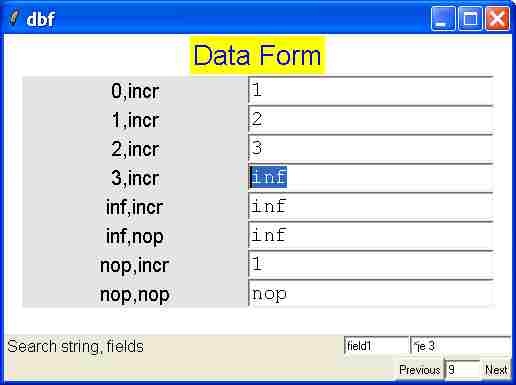
The dbf window
dbcurrentand there is an array maintained with entries for each field, which is normally hidden.The procedure dbform is the form generator, which takes at least one argument as the current entry shown from the database. By changing the dbcurrent variable, and calling the the dbform procedure, changes can be made to the current entry.
(Tcl) 125 % puts $dbcurrent
{one {}} {two {}} {three {}}
(Tcl) 126 % set dbcurrent {{one {1}} {two {}} {three {}}}
{one {1}} {two {}} {three {}}
(Tcl) 127 % dbformMakes the content of the first of three entries "1" instead of empty, which could of course also be achieved by typing "1" in the corresponding entry. This way however, a procedure can change the current entry, and update the view window.The main variable dbvar will be updated with the new entry when navigation controls are used, which can be easily verified by usingputs [lindex $dbvar $newcurrententry]Where the numerical variable newcurrententry is the textvariable of the entry field in the form.The following window is shown when calling the procedure
dbcontrol databasefilewhere databasefile is a filename which can be {}±LV [It looks, to me, like something is missing in the previous line...]
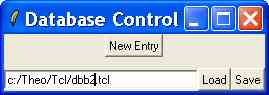
''The dbf window''
Searching the database in text form edit
The function (in Tcl, everything returns a list, though outside-procedure access and modification can occur, so they can be strict functions with multiple return values or procedures) to search in the database is: dbsearch {pattern} {fieldnames {}} {range {0 end}}for instance in a database with addresses we would have (Tcl) dbsearch *mith
{4 name smith}
{5 name smith}
{6 building {Smithsonian alpha}}
{7 name {John Smith}}Where in entry 4,5,6 and 7 of my little example database we find a matching field.To retrieve only the names Smith: (Tcl) dbsearch *Smith* name
{7 name {John Smith}}Routines with short explanation edit
The following routines are taken straight from the Bwise library, or in fact just a single under 100k tcl script. proc dbaccess { {title {New Database}} {file {tdb.tcl}} {fields {{Name name} {Data "Data field"}}} {adbvar {dbvar}} } {
global dbcurrent $adbvar currententry newcurrententry;
if {[file exists $file] == 1} {
set f [open $file r]; set dbvar [read $f]; close $f
};
set currententry 0
set newcurrententry $currententry
set dbcurrent [lindex $dbvar $currententry];
if {[winfo exists .tc] == 0} {
toplevel .tc; canvas .tc.c ; pack .tc.c -expand y -fill both;
}
dbform $dbcurrent;
}
proc dbcontrol { {n} } {
global dbname
toplevel .dbc
wm title .dbc "Database Control"
set dbname $n
set w .dbc
frame $w.f
entry $w.f.e -textvar dbname -width 30
button $w.f.s -text Save -command {
global dbname currententry dbvar;
display_entry $currententry
set f [open $dbname w];
puts $f $dbvar; close $f
}
button $w.f.l -text Load -command {
global dbname
dbaccess [lindex [file split [file rootname $dbname]] end] $dbname
}
bind $w.f.e <Double-Button> {
set textname [tk_getOpenFile]
}
pack $w.f -side bottom -expand n -fill x
pack $w.f.e -side left -expand y -fill x
pack $w.f.s -side right
pack $w.f.l -side right
button $w.bnew -text "New Entry" -command {
global dbvar newcurrententry
set tt [lindex $dbvar $currententry]
append dbvar " {"
foreach i $tt {
append dbvar [list [list [lindex $i 0] {}]] \
}
append dbvar "}"
set newcurrententry [expr [llength $dbvar]-1]
eval [bind .dbf.wb.ee <Return>]
}
pack $w.bnew
}
proc dbform { {fields} {title {Data Form}} {window {.dbf}} {fw {20}} {ew {20}} } {
global dbcurrent ccontent cname cvars currententry
global searchstring searchfields
if {[winfo exists $window] == 0} {toplevel $window} {foreach i [winfo children $window] {destroy $i} };
$window conf -bg white;
label $window.t -text $title -font "helvetica 20" -bg yellow -fg blue;
pack $window.t -anchor n -padx 2 -pady 2;
list2array $fields
foreach i $cvars {
set wn [string tolower $i];
# onefield $window.$wn $cname($i) ccontent($i) $fw $ew;
onefield $window.$wn $i ccontent($i) $fw $ew;
}
global currententry newcurrententry
frame $window.wb; pack $window.wb -side bottom -anchor s -fill x -expand n
button $window.wb.ne -text Next -command {
global newcurrententry dbvar
if {$newcurrententry < [expr [llength $dbvar] -1]} {incr newcurrententry}
display_entry $newcurrententry
}
pack $window.wb.ne -side right
button $window.wb.pre -text Previous -command {
global newcurrententry
incr newcurrententry -1
if {$newcurrententry < 0} {set newcurrententry 0}
display_entry $newcurrententry
}
entry $window.wb.ee -width 5 -textvar newcurrententry
pack $window.wb.ee -side right
bind $window.wb.ee <Return> {
global newcurrententry currententry dbvar
if {$newcurrententry > [expr [llength $dbvar] -1]} {
set newcurrententry $currententry }
if {$newcurrententry < 0 } { set newcurrententry $currententry }
display_entry $newcurrententry
}
pack $window.wb.pre -side right
frame $window.ws; pack $window.ws -side bottom -anchor s -fill x -expand n
label $window.ws.l -text "Search string, fields" -font "helvetica 12"
pack $window.ws.l -side left
entry $window.ws.es -textvar searchstring -width 16
pack $window.ws.es -side right
entry $window.ws.ef -textvar searchfields -width 10
pack $window.ws.ef -side right
bind $window.ws.es <Return> {
global newcurrententry;
set newcurrententry [lindex [lindex [dbsearch $searchstring $searchfields [list [expr $newcurrententry+1] end]] 0] 0];
set t [bind .dbf.wb.ee <Return>];
eval $t
}
}
proc dbsearch { {pattern} {fieldnames {}} {range {0 end}} } {
global dbvar
set r {}
set i [lindex $range 0]
foreach d [eval "lrange [list $dbvar] $range"] {
foreach e $d {
if {$fieldnames != {}} {
foreach f $fieldnames {
if [string match $f [lindex $e 0]] {
if [string match $pattern [lindex $e 1]] {
append r [list [list $i [lindex $e 0] [lindex $e 1] ]] \n
}
}
}
} {
if [string match $pattern [lindex $e 1]] {
append r [list [list $i [lindex $e 0] [lindex $e 1] ]] \n
}
}
}
incr i
}
return $r
}
proc display_entry { {n} } {
global dbcurrent currententry dbvar
set dbcurrent [array2list]
update_entry
set currententry $n
set dbcurrent [lindex $dbvar $currententry]
set pf [focus -lastfor .dbf]
dbform $dbcurrent
set t "focus $pf" ; catch $t
update
set t "$pf selection range 0 end" ; catch $t
update
set t "$pf icursor end" ; catch $t
} The example database I used above can be made by pasting this tcl command in the interpreter: set dbvar {{{mapping newstate} nop} {{mapping output} {}} {{state out} nop} {{Entry1 out} nop}} {{{mapping newstate} 1} {{mapping output} 0} {{state out} nop} {{Entry1 out} incr}} {{{mapping newstate} {}} {{mapping output} {}} {{state out} {}} {{Entry1 out} {}}} {{name {}} {smith {}}} {{name smith}} {{name smith} {address {lane 1}}} {{name jones} {building {Smithsonian alpha}}} {{name {John Smith}} {address {lane 2}}}LV so you build an in-core database of data, and do things with it. Then you have some sort of serialization process so it can be written out and read back in later?
LV What other in-core database technologies exist? Is SQLite one? Metakit is a disk based database.AK: Metakit - Yes, but uses memory mapping to make access more efficient. This is quite near to in-memory.
TV I made an in code synthesizer sound database years ago which was in core for the ST, which of course wasn't in tcl. I don't know another, I didn't see one when browsing a significant portion of tcl resources that means.The rest will be mainly answered above, probably. The serialisation is possible based on list entries, I use a variable for the 'currently edited' field.AK: ST most likely refers to the 'Atari 1400 ST'. I had one too.TV: Mine was a 260 first, which was sort of a 520, and then of course I had to solder in the rest of the 1024 kilobytes of wonderfull linear 68000 memory. No real pentium ancestor was ever used professionally, I guess.
27mar03 jcw - In-core databases are way under-appreciated IMO (btw, I initially read this page as "in the Tcl core"...).But unless you address persistent storage, it'll all be gone with a single power off/failure or system hang/crash. Once you do consider that side of things, you'll have to address failsafe/transaction logic. And if it gets really big, and apps get launched and exit again, then load/save overhead of full serialization will start to matter. Then there is the fact that current in-memory representations of large datasets are not very efficient (because they do not take advantage of the fact that such sets are usually very homogenous). Another aspect which tends to be overlooked is that associative memory (and pointer-based, and OO-centric, structures) assumes traversal always works from the same key field, unlike the relational data model, which decouples data model design from usage patterns and "navigation".By the time you address all the above... you end up with the equivalent of a database system again.IMO, the solution is not to re-invent this wheel, but to look far ways in which persistent data can be used 100% transparently. The Perl "tie" mechanism is a good example of this, in Tcl terms it is equivalent to having an array of which the data happens to be stored on disk. I agree strongly with the intent of all this btw, i.e. that access/modify code should not be littered all over application scripts and logic.This seems like a good spot to point to the Tequila package, which is showing its age but in a way still as applicable and practical as ever.AK: Another model here is that of Tuplespaces.
TV As I wrote, I did this stuff, which not btw was not without regard for the context of other Tcl work (and certainly previous C work), rather quickly, and found it major satisfactory to have the engine of tcl run quite capably and powerfully in no time, not needing much else.An important design consideration in all this is that one always has to do with disc access bandwidth and granularity, so that if one wants unique and general (unkeyed) searches over a significant portion of the database, probably a large part of the data has to pass to the relatively low bandwidth disc to memory channel once per search. Which makes all other speed considerations subdued to that major criterion, no matter how good one programs or what oo or not datastructures are added to the basic data.In that respect (as I´ll add in the text above) the integral saving of the whole database at times when one wants combined with straightforward logging is not a bad way to go get those disc stream dma units working in one long haul, and at least disc access bandwidth is used as optimal as that gets.
LV What other in-core database technologies exist? Is SQLite one? Metakit is a disk based database.AK: Metakit - Yes, but uses memory mapping to make access more efficient. This is quite near to in-memory.
TV I made an in code synthesizer sound database years ago which was in core for the ST, which of course wasn't in tcl. I don't know another, I didn't see one when browsing a significant portion of tcl resources that means.The rest will be mainly answered above, probably. The serialisation is possible based on list entries, I use a variable for the 'currently edited' field.AK: ST most likely refers to the 'Atari 1400 ST'. I had one too.TV: Mine was a 260 first, which was sort of a 520, and then of course I had to solder in the rest of the 1024 kilobytes of wonderfull linear 68000 memory. No real pentium ancestor was ever used professionally, I guess.
27mar03 jcw - In-core databases are way under-appreciated IMO (btw, I initially read this page as "in the Tcl core"...).But unless you address persistent storage, it'll all be gone with a single power off/failure or system hang/crash. Once you do consider that side of things, you'll have to address failsafe/transaction logic. And if it gets really big, and apps get launched and exit again, then load/save overhead of full serialization will start to matter. Then there is the fact that current in-memory representations of large datasets are not very efficient (because they do not take advantage of the fact that such sets are usually very homogenous). Another aspect which tends to be overlooked is that associative memory (and pointer-based, and OO-centric, structures) assumes traversal always works from the same key field, unlike the relational data model, which decouples data model design from usage patterns and "navigation".By the time you address all the above... you end up with the equivalent of a database system again.IMO, the solution is not to re-invent this wheel, but to look far ways in which persistent data can be used 100% transparently. The Perl "tie" mechanism is a good example of this, in Tcl terms it is equivalent to having an array of which the data happens to be stored on disk. I agree strongly with the intent of all this btw, i.e. that access/modify code should not be littered all over application scripts and logic.This seems like a good spot to point to the Tequila package, which is showing its age but in a way still as applicable and practical as ever.AK: Another model here is that of Tuplespaces.
TV As I wrote, I did this stuff, which not btw was not without regard for the context of other Tcl work (and certainly previous C work), rather quickly, and found it major satisfactory to have the engine of tcl run quite capably and powerfully in no time, not needing much else.An important design consideration in all this is that one always has to do with disc access bandwidth and granularity, so that if one wants unique and general (unkeyed) searches over a significant portion of the database, probably a large part of the data has to pass to the relatively low bandwidth disc to memory channel once per search. Which makes all other speed considerations subdued to that major criterion, no matter how good one programs or what oo or not datastructures are added to the basic data.In that respect (as I´ll add in the text above) the integral saving of the whole database at times when one wants combined with straightforward logging is not a bad way to go get those disc stream dma units working in one long haul, and at least disc access bandwidth is used as optimal as that gets.


